Brief Preparation: What is Tagging?
Tagging, in general, refers to the setup and configuration of web analytics and marketing tracking implementations, such as Google Analytics or the Facebook / Meta Pixel. Each individual logical unit (e.g., “sending a pageview to Google Analytics”) is considered a tag.
Typically, a tag manager is used for this purpose. A tag manager is a piece of software that makes configuring these setups easier, ensuring that everything doesn’t need to be programmed manually, but rather can be set up via a convenient interface. The most popular tag manager is Google Tag Manager, but others like Tealium, the Matomo Tag Manager, and a few more also exist.
The Classic Approach: Client Side Tagging
In this context, “client” simply refers to the browser.
Client-side tagging means:
- The control of tracking, i.e., determining what data is sent, when, and where, is managed via JavaScript in the user’s browser.
- The tracking data are sent directly from the user’s browser to the data recipient without any detours.
For instance, the browser sends a “pageview” event directly to
www.google-analytics.com.
Simply put, the process looks like this:
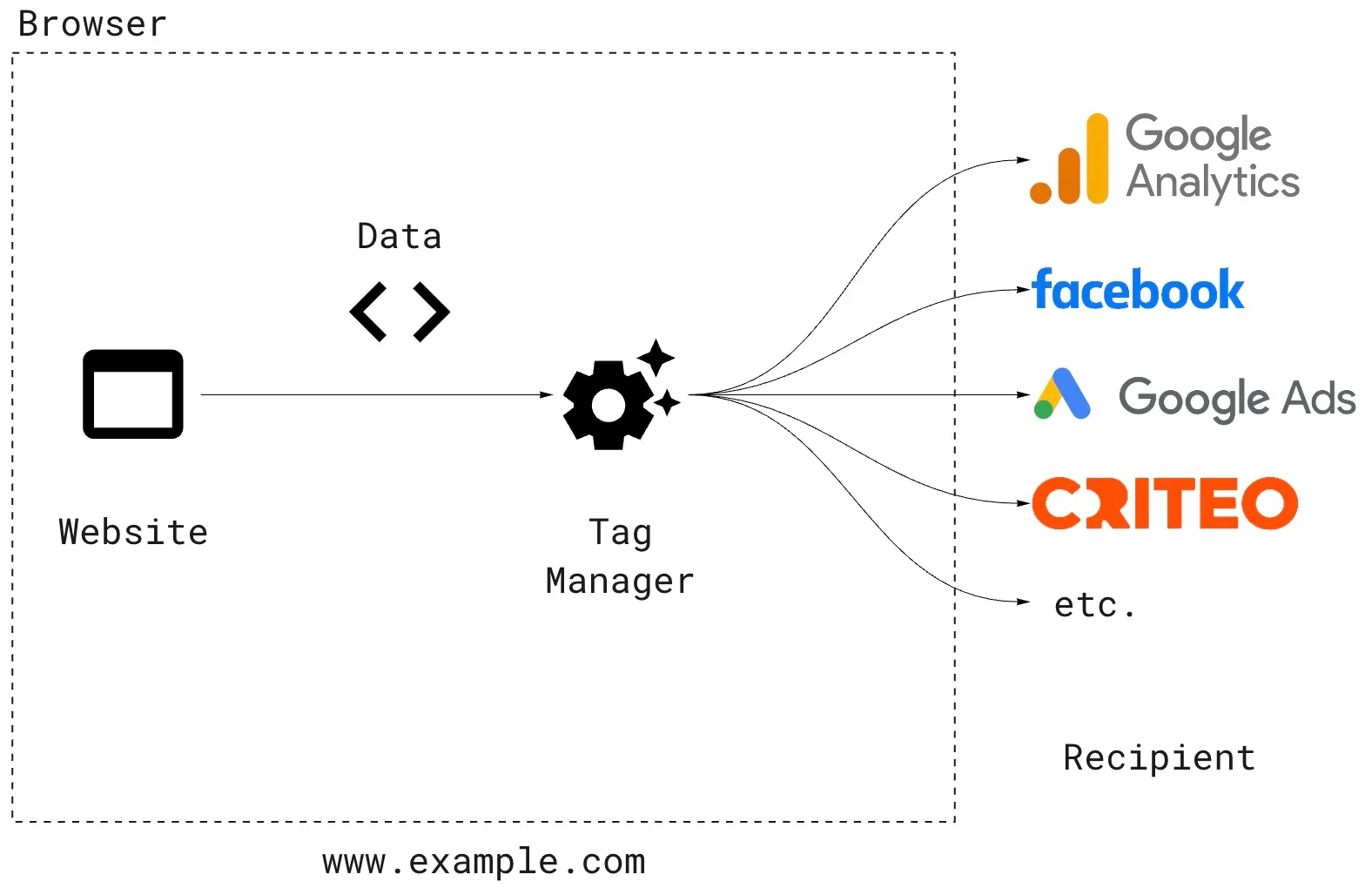
This has been the standard solution since the inception of tracking – this is how data has always been collected.
However, the problems with this approach have become more apparent over the years:
Problem 1: Lack of Privacy Protection
With client-side tagging, website operators have limited control over the exact data that reaches the data recipient. For example, to implement Facebook tracking, a JavaScript file from Facebook’s servers is loaded, and its functionality can change at any time, often without notice.
Even with diligent tracking configuration, control over some data is not possible. For instance, when the browser sends data to facebook.com, it inevitably includes:
- The user’s IP address
- The name and version of the browser (part of the so-called “User-Agent”)
- Cookies
These are technically unavoidable and pose a privacy issue, as these are considered personal data, especially under regulations like GDPR.
Problem 2: Poor Data Quality
Data quality is closely linked to privacy concerns and is influenced primarily by two developments:
Adblockers
An increasing number of users deploy ad blockers that often block not just advertisements but also purely analytical tracking, even if most users would not be bothered by the latter.
Anti-Tracking Measures by Browser Manufacturers
Several browser manufacturers have developed rules to protect their users’ privacy, specifically to limit cross-site tracking. Safari (Apple) and Firefox (Mozilla), along with stricter niche browsers like Brave, are leading this movement. Even as a tracking professional reliant on data collection, I see these developments as positive and a step in the right direction.
Google Chrome, which has the largest market share, has not yet adopted these restrictions. While disappointing, this is understandable, considering Google generates over 90% of its revenue from online advertising.
Problem 3: Load Times & Performance
Running analytics and marketing tracking on websites involves extensive, often unoptimized JavaScript. This demands significant processing power, noticeably impacting user experience, especially on older smartphones.
Moreover, the bandwidth consumed by tracking data detracts from that available for essential website content—text, images, videos—slowing down site loading times.
The Evolution: Server Side Tagging
The solution to these problems is server-side tagging. This approach adds an additional step to the process described earlier, involving a tagging server:
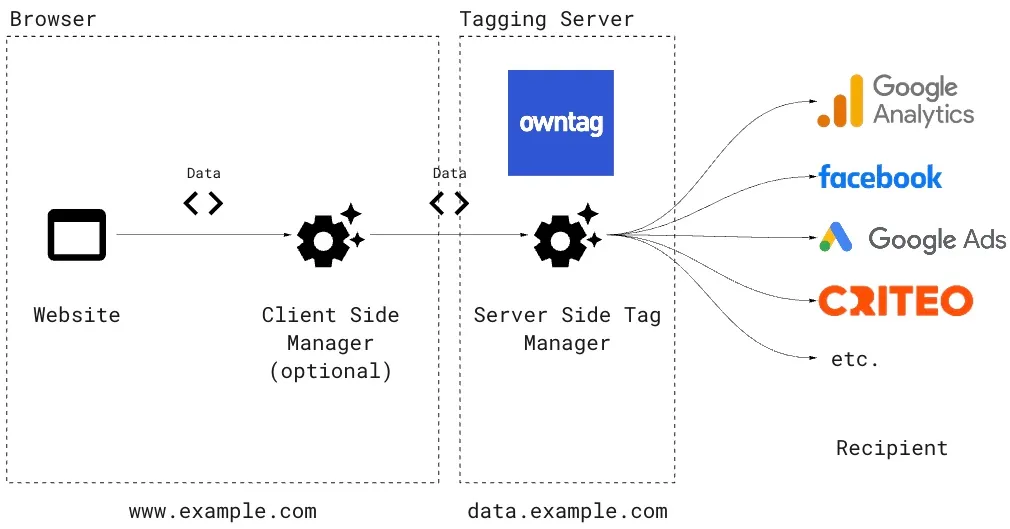
Instead of sending data directly from the user’s browser to the data recipient, it’s first sent to the tagging server, then relayed from there to the final recipient.
The tagging server is legally and organizationally part of the website operator’s infrastructure, meaning in the initial stage, data doesn’t leave their domain.
One could also refer to the tagging server as a “server-side tag manager,” as it assumes similar responsibilities to a browser-based tag manager. It processes incoming data, possibly converts it into the appropriate format, and then forwards it.
Technically, a server-side tag manager is a program that runs continuously on a server, waiting for incoming tracking events. When these arrive, they are processed and forwarded. The configuration of tags, triggers, and variables determines how they are processed and where they are sent, a task typically handled by technical marketers or web analysts (like you!).
This infrastructure setup offers significant advantages:
Advantage 1: Privacy Through Full Control
The tagging server does more than just relay data; it allows for data manipulation en route to its destination. Information within the data can be supplemented, edited, or even removed. For instance, data recipients like Google Analytics technically receive data not from the user, but from the tagging server, seeing only its IP address, which is irrelevant for privacy concerns.
Consider the user agent example, a unique browser identifier automatically sent by the browser:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36The tagging server could be configured to extract only analytically relevant information (“Chrome”) and discard the rest, adhering to the principle of data minimization by collecting only necessary user data.
Advantage 2: More Comprehensive Data
Browser restrictions on client-side tracking, while potentially frustrating, are judiciously designed to allow data collection under user-friendly and secure conditions. Some examples:
Longer Cookie Durations
Safari and Firefox limit the lifespan of JavaScript-set cookies to 7 days, hindering the ability to recognize users over extended periods. However, longer durations can be achieved with HTTP cookies set by the tagging server. Uniquely, HTTP cookies can be configured to be inaccessible to scripts embedded in the website (using the “httpOnly” flag), making the information within the cookie more secure.
Reduced Impact from Adblockers
Adblockers aim to block uncontrolled data outflow from the browser, including to external domains like google-analytics.com. However, they typically don’t block data sent to a domain owned by the organization, such as daten.beispiel.de.
Advantage 3: Better Browser Performance, with the Tagging Server Handling the Work
With client-side tagging, each tracked event and each connected tracking recipient requires a data packet to leave the browser. On tracking-intensive sites, this can result in hundreds of outbound requests:
For example, the homepage of spiegel.de generates over 350 requests upon loading, most for analysis and advertising tracking. The 4.4 MB of transferred data would have filled 3 floppy disks in the past.
With server-side tagging, theoretically, information (e.g., “Product X added to cart”) needs to be sent from the browser to the tagging server only once. From there—without negatively impacting user experience—it’s distributed multiple times to respective recipients. The computational and bandwidth demands remain the same, but now the website operator appropriately bears them.
What Doesn’t a Tagging Server Do?
Server-side tagging isn’t a means to evade legal and ethical obligations in data collection. The fact that data pathways are no longer traceable in the browser but occur invisibly on the tagging server has no bearing on privacy requirements.
Most tracking will still require user consent. Thus, server-side tagging isn’t a route to “consentless tracking.”
How Does This Relate to owntag – What Do You Do?
The most popular and widespread server-side tag manager is Google Tag Manager’s Server-Side Container. It operates by allowing you to configure your tags, triggers, and variables on Google’s interface at tagmanager.google.com, much like the Web Container. However, the actual execution of this configuration occurs on a server of your choosing. Google provides a 64-character “Container Configuration,” essentially an address, enabling the tagging server to retrieve your configuration from tagmanager.google.com.
Setting up your own Google Tag Manager Server-Side Container with a cloud hosting provider has been complex and largely the domain of DevOps experts. This is compounded by the ongoing efforts required for monitoring and updates, not to mention the complex questions regarding the impact of hosting on privacy.
owntag addresses these challenges:
- With owntag, anyone can host a Server Side GTM Container – just a few clicks and it’s set up in minutes.
- owntag takes care of monitoring, ensuring your container runs reliably.
- owntag’s straightforward pricing model makes budgeting for your SGTM setup much simpler.
- Privacy is a priority at owntag – that’s why we exclusively host on European cloud infrastructure.
In our “First Steps” guide, you can see how easy it is to host an SGTM Container with owntag.
→ Create your own owntag account now and immediately test your own SGTM Container for free.